About the InstructLab Taxonomy¶
InstructLab 🐶 uses a novel synthetic data-based alignment tuning method for Large Language Models (LLMs.) The "lab" in InstructLab 🐶 stands for Large-Scale Alignment for ChatBots1.
The LAB method is driven by taxonomies, which are largely created manually and with care. Taxonomies allow you to create models tuned with your data (enhanced via synthetic data generation) using the LAB 🐶 method.
The instructlab/taxonomy repository contains a comprehensive taxonomy tree that we use to build the overall model. You are welcome to contribute to it!
Skills and Knowledge¶
In a taxonomy, we have "skills," or performative actions, and "knowledge," or based more on answering questions that involve facts, data, or references. Learn more about knowledge in the knowledge guide, and learn more about skills in the skills guide.
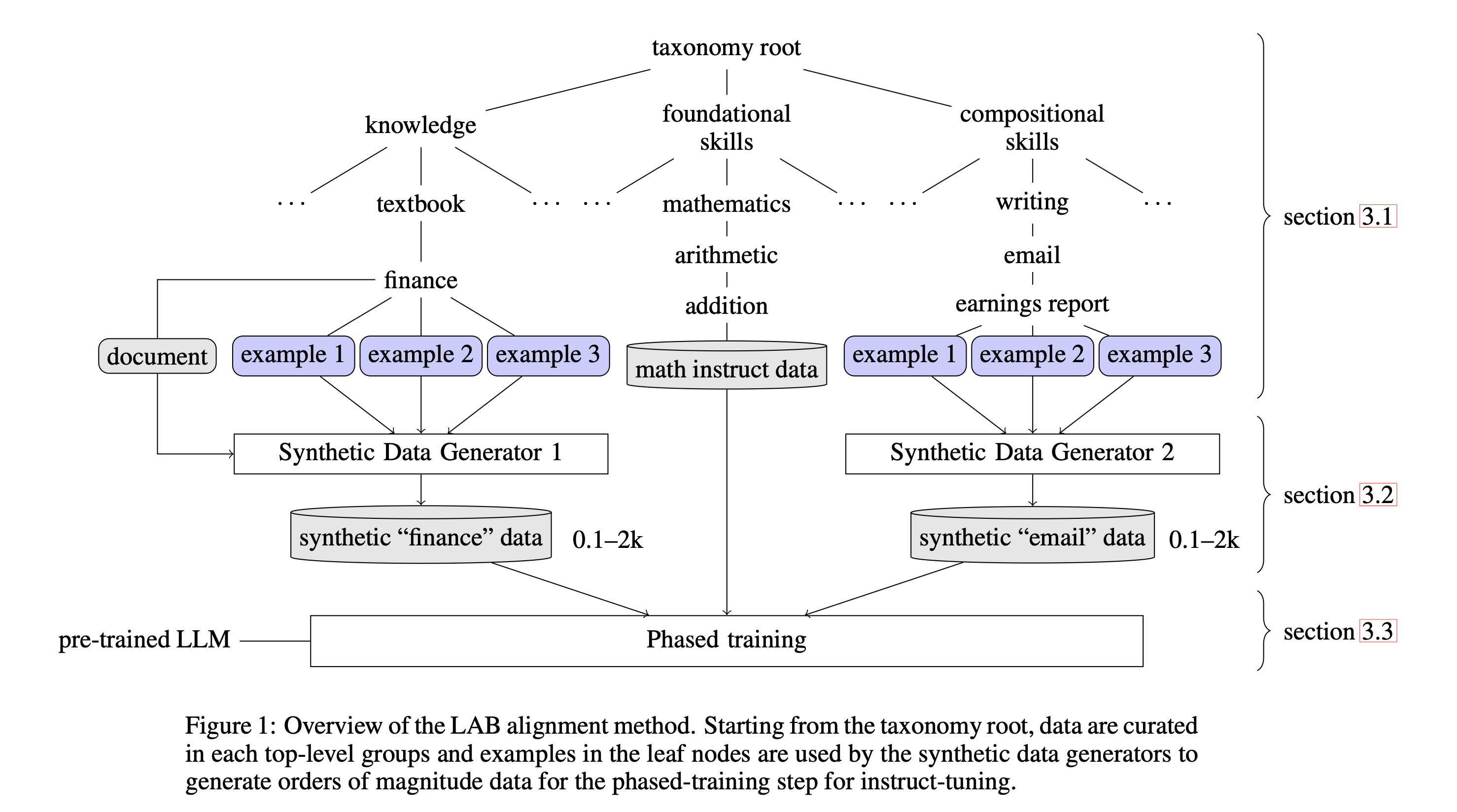
Taxonomy trees¶
The overall structure of a taxonomy tree for InstructLab is a cascading file structure. The top-level directory is called the "root" of the tree. The resulting subdirectories are "branches" of the tree. Along a branch are more nested directories until we reach the final directory. That final directory along a branch is called the "leaf node," and it contains a YAML file named qna.yaml and, in the case of the upstream taxonomy, an attribution.txt file that holds citation information. The only required file in a leaf node directory for the InstructLab process is the qna.yaml file. You can learn more about the structure of the qna.yaml file in the knowledge and skill guides.
Tree structure¶
The tree structure is important because it is used by the synthetic data generation process to relate chunks of knowledge together. Without it, training would not be as accurate.
The root of a taxonomy tree does not need to be the root of all knowledge. The only requirements for a taxonomy tree are that
- knowledge is within a
knowledgedirectory - ungrounded compositional skills are within a
compositional_skillsdirectory - grounded compositional skills are within a
compositional_skills/grounded/directory structure - the
knowledgeandcompositional_skillsdirectories are within a single root directory
This helps the synthetic data generation process and training process parse the files in the right order.
Sorting knowledge and skills¶
For each piece of knowledge, you should have a single qna.yaml file. For example, if you are fine-tuning a model to talk about cloud formations, you would make a leaf node directory for each type of cloud formation (e.g., cumulonimbus, cirrus, cumulus, incus, lenticular) and then have a qna.yaml file dedicated to each formation with a document for each one. You would not lump all the cloud formations together into one YAML file with five or six documents as sources as the synthetic data generation process would not group the resulting data based on cloud formation, thereby making the resulting model possibly provide information about one cloud formation when asked about another.
The same thought applies to skills. A single skill should be in one leaf node directory, even if it is related to another skill. Do not create a qna.yaml file that has multiple skills in it.
The upstream taxonomy¶
We have a comprehensive taxonomy tree in the InstructLab project used to build the community model. We welcome contributions to that taxonomy. Here's more information on how that tree is structured.
Upstream tree domain classification¶
In general, we use the Dewey Decimal Classification (DDC) System to determine our domains (and subdomains) in the overall taxonomy. This DDC SUMMARIES document is a great resource for determining where a topic might be classified.
Generally, expect that there may be several layers you need to add to the taxonomy tree when adding knowledge or skills. For example, if you were to write a knowledge submission about a constellation, you would need to add directories to the tree, primarily astronomy/constellations/ inside the knowledge/science/ branch, before you would add your submission. These are "branches", with your submission as a "leaf node." The taxonomy is very much like a tree.
If you are unsure where to put your knowledge or compositional skill, create a folder in the miscellaneous_unknown folder under the knowledge or compositional_skills folders.
Upstream taxonomy tree layout¶
The taxonomy tree is organized in a cascading directory structure. At the end of each branch, there is a YAML file (qna.yaml) that contains the examples for that domain along with any attribution files (attribution.txt). Maintainers can decide to change the names of the existing branches or to add new branches.
Important
Folder names do not have spaces. Use underscores between words.
Taxonomy diagram¶
Note
These diagrams show subsets of the taxonomy. They are not a complete representation.
In this diagram, a subset of a taxonomy for InstructLab demonstrates the branch-and-leaf-node structure.
flowchart TD;
na[not accepting contributions\n at this time]:::na
taxonomy --> foundational_skill & compositional_skills & knowledge
foundational_skill:::na --> reasoning:::na
reasoning:::na --> common_sense_reasoning:::na
reasoning:::na --> mathematical_reasoning:::na
reasoning:::na --> theory_of_mind:::na
compositional_skills --> engineering
compositional_skills --> grounded
compositional_skills --> lingustics
grounded --> grounded/arts
grounded --> grounded/geography
grounded --> grounded/history
grounded --> grounded/science
knowledge --> knowledge/arts
knowledge --> knowledge/miscellaneous_unknown
knowledge --> knowledge/science
knowledge --> knowledge/technology
knowledge/science --> animals --> birds --> black_capped_chickadee --> black_capped_chickadee-a & black_capped_chickadee-q
knowledge/science --> astronomy --> constellations --> phoenix --> phoenix-a & phoenix-q
black_capped_chickadee-a{attribution.txt}
black_capped_chickadee-q{qna.yaml}
phoenix-a{attribution.txt}
phoenix-q{qna.yaml}
classDef na fill:#EEEHere is an illustrative directory structure to show how the taxonomy is laid out in the practical sense:
.
└── linguistics
├── writing
│ ├── brainstorming
│ │ ├── idea_generation
| │ └── qna.yaml
│ │ attribution.txt
│ │ ├── refute_claim
| │ └── qna.yaml
│ │ attribution.txt
│ ├── prose
│ │ ├── articles
│ │ └── qna.yaml
│ │ attribution.txt
└── grammar
└── qna.yaml
│ attribution.txt
└── spelling
└── qna.yaml
attribution.txt
Contribute knowledge and skills to the taxonomy¶
The ability to contribute to a Large Language Model (LLM) has been difficult in no small part because it is difficult to get access to the necessary compute infrastructure.
The taxonomy repository will be used as the seed to synthesize the training data for InstructLab-trained models. We intend to retrain the model(s) using the main branch following InstructLab's progressive training on a regular basis. This enables fast iteration of the model(s), for the benefit of the open source community.
By contributing your skills and knowledge to this repository, you will see your changes built into an LLM within days of your contribution rather than months or years! If you are working with a model and notice its knowledge or ability lacking, you can correct it by contributing knowledge or skills and check if it's improved after your changes are built.
While public contributions are welcome to help drive community progress, you can also fork this repository under the Apache License, Version 2.0, add your own internal skills, and train your own models internally. However, you might need your own access to significant compute infrastructure to perform sufficient retraining.
Ways to contribute¶
You can contribute to the taxonomy in the following two ways:
- Adding new examples to existing leaf nodes:
- Adding new branches/skills corresponding to the existing domain:
For more information, see the Ways of contributing to the taxonomy repository documentation.
How to contribute skills and knowledge¶
To contribute to the repo, you'll use the Fork and Pull model common in many open source repositories. You can add your skills and knowledge to the taxonomy in multiple ways; for additional information on how to make a contribution, see the Documentation on contributing. You can also use the following guides to help with contributing:
- Contributing using the GitHub webpage UI.
- Contributing knowledge to the taxonomy in the Knowledge contribution guidelines.
Why should I contribute?¶
This taxonomy repository will be used as the seed to synthesize the training data for InstructLab-trained models. We intend to retrain the model(s) using the main branch as often as possible (at least weekly). Fast iteration of the model(s) benefits the open source community and enables model developers who do not have access to the necessary compute infrastructure.
-
Shivchander Sudalairaj, Abhishek Bhandwaldar, Aldo Pareja, Kai Xu, David D. Cox, Akash Srivastava. "LAB: Large-Scale Alignment for ChatBots", arXiv preprint arXiv: 2403.01081, 2024. (* denotes equal contributions) ↩