Community Model Build Process
Note
This document is the Community Build Process, these are the general steps to get the cmb built.
If you are looking for the config.yaml that worked for granite-3.0-8b-base there it is.
Community Model Build diagram¶
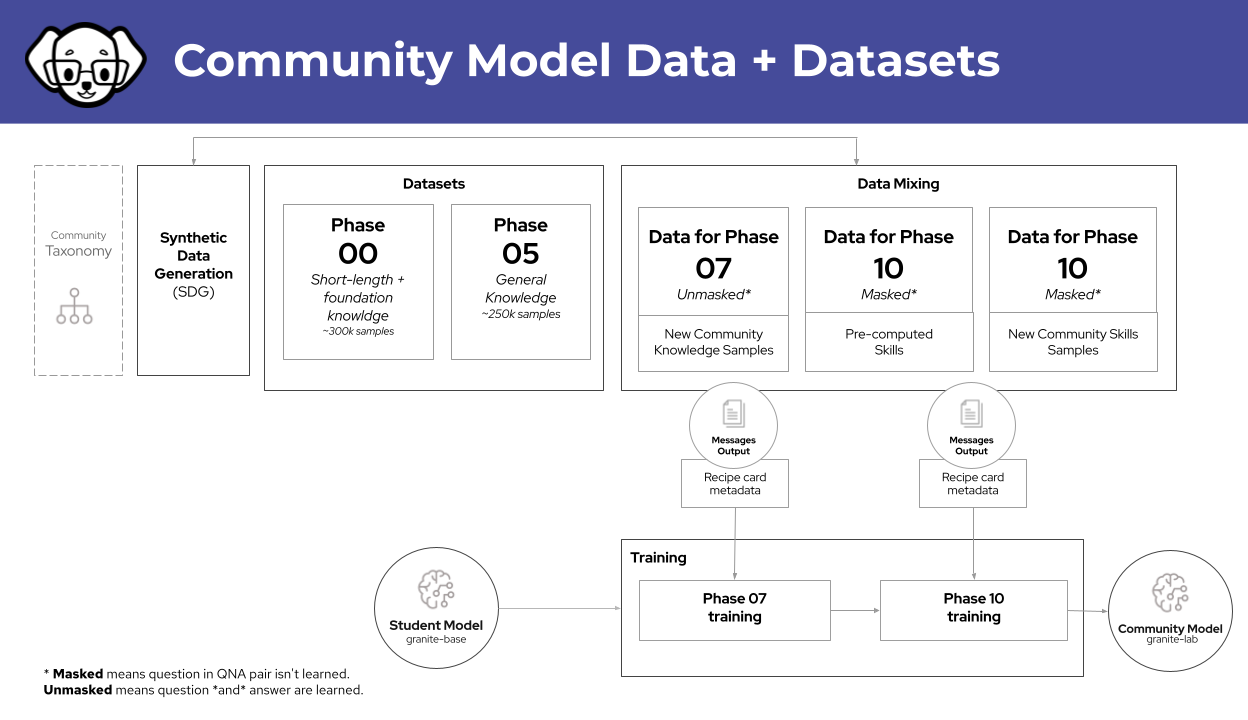
We have created a default build.sh script, which will live in a repository (soon). The actual commands are
explained here, and this should be considered the source of truth.
Add the PRs to the build machine's taxonomy tree¶
Add the PRs you want to be built into the run. Tag the PRs with "cmb-running."
Example:
mkdir -p compositional_skills/general/synonyms
vi compositional_skills/general/synonyms/attribution.txt
vi compositional_skills/general/synonyms/qna.yaml
cd ~/.local/share/instructlab/taxonomy
git fetch origin pull/ID/head:BRANCH_NAME
git checkout BRANCHNAME
Verify changes¶
ilab taxonomy diff
Warning
~/.local/share/instructlab/datasets -- should be empty before starting
Every gpu should be "empty", or 0% check with nvidia-smi
Note
These steps were tested on the a100 x8 machine that was given to the team as of Dec
3rd, 2024. If you have different hardware you'll need a different profile, and different
options.
Reset the build directories¶
Move the old build directories away, or save them. Something along these lines:
mv /home/instructlab/.local/share/instructlab/phased/journalfile.yaml /home/instructlab/.local/share/instructlab/phased/journalfile.yaml_$DATE
mv /home/instructlab/.local/share/instructlab/datasets /home/instructlab/.local/share/instructlab/datasets_$DATE
mv /home/instructlab/.local/share/instructlab/phased /home/instructlab/.local/share/instructlab/phased_$DATE
Create the directories you moved away:
mkdir /home/instructlab/.local/share/instructlab/phased
mkdir /home/instructlab/.local/share/instructlab/datasets
Add the instructlab_community mixin¶
For the community build, off the base model, you should add the community data set, these are the steps:
cd ~/.local/share/instructlab/datasets/
wget https://huggingface.co/datasets/instructlab/InstructLabCommunity/resolve/main/instructlab_community.jsonl
cd ~
Modify your config¶
ilab config edit
find the general section of your config and ensure it matches the following:
general:
# Debug level for logging.
# Default: 0
debug_level: 0
# Log format. https://docs.python.org/3/library/logging.html#logrecord-attributes
# Default: %(levelname)s %(asctime)s %(name)s:%(lineno)d: %(message)s
log_format: '%(levelname)s %(asctime)s %(name)s:%(lineno)d: %(message)s'
# Log level for logging.
# Default: INFO
log_level: INFO
# Use legacy IBM Granite chat template (default uses 3.0 Instruct template)
# Default: False
use_legacy_tmpl: true
use_legacy_tmpl must be true in order to generate data for and train the granite-3.0-8b-base model
Create the data¶
# annouce the start of the SDG
ilab data generate --pipeline full --gpus 8
# annouce the completion of the SDG
Run the training after the generate is complete¶
# annouce the start of the training
ilab model train --strategy lab-multiphase --phased-phase1-data /home/instructlab/.local/share/instructlab/datasets/knowledge_train_msgs_*.jsonl --phased-phase2-data /home/instructlab/.local/share/instructlab/datasets/skills_train_msgs_*.jsonl --skip-user-confirm --force-clear-phased-cache
# annouce the completion of the training
(optional) Post training evaluation steps¶
If you want to send a sanity check, you can set these two variables to do a subset of the training:
export INSTRUCTLAB_EVAL_FIRST_N_QUESTIONS=10 # mtbench
export INSTRUCTLAB_EVAL_MMLU_MIN_TASKS=true # mmlu
(In case of sanity of a specific Sample Model creation)
ilab model evaluate --benchmark mt_bench --model ~/.local/share/instructlab/checkpoints/hf_format/samples_XXXXXX
Tip
We should do the revaluation because we want to reverify the numbers before going any farther.
General Benchmarking¶
mmlu: general model knowledge, general facts, it's a knowledge number out of 100mt_bench: is a skill based, extraction, etc, out of 10
Note
we want around 7.1 for mt_bench average for a model candidate
Specific Benchmarking¶
mmlu_branch: these are specific to the general knowledge
ilab model evaluate --benchmark mmlu_branch --model ~/.local/share/checkpoints/hf_format/<checkpoint> --tasks-dir ~/.local/share/instructlab/datasets/<node-dataset> --base-model ~/.cache/instructlab/models/granite-7b-redhat-lab
mt_bench_branch: these are specific for the skills
ilab model evaluate --benchmark mt_bench_branch --model ~/.local/share/checkpoints/hf_format/<checkpoint> --taxonomy-path ~/.local/share/instructlab/taxonomy --judge-model ~/.cache/instructlab/models/prometheus-8x7b-v2-0 --base-model ~/.cache/instructlab/models/granite-7b-redhat-lab --base-branch main --branch main
Publish to Huggingface¶
Sanity check the model to make sure it does what you are expecting:
ilab model chat --model /home/instructlab/.local/share/instructlab/phased/phase2/checkpoints/hf_format/samples_XXXXX
Copy the checkpoint to the repository directory:
cp /home/instructlab/.local/share/instructlab/phased/phase2/checkpoints/hf_format/samples_XXXX/* ~/huggingface_repos/granite-3.0-8b-lab-community/
Add and commit the changes to the repository:
cd ~/huggingface_repos/granite-3.0-8b-lab-community/
git add .
git commit -s
git push origin main
Congratulations, this is the core steps to building out the safe-tensors to publish to hugging face.